These days it’s probably easier to track down the mythical Yeti than to find a software organization that hasn’t adopted some form of agile practices.
The industry-wide shift to agile came with plenty of promised benefits. Not only did we expect to see an increase in both productivity and software quality; we also got sold on the idea that agile lets us adapt faster to changed circumstances such as user feedback and rapid shifts in how we interpret our requirements. However, those expected wins are not necessarily the way most agile transformations turn out.
One common reason for all unrealized benefits is the lack of feedback loops. Feedback loops inform us about the ever-changing state and health of our system. And by system I’m referring to the technical aspects – our code and design – in combination with the socio-technical organizational aspects of software development at scale. A healthy system balances both.
In this article we focus on a central, and often neglected, practice with the potential of providing the necessary feedback: Retrospectives. We discuss why retrospectives get abandoned, how you avoid that fallacy by keeping retrospectives relevant, and we’ll do it by embracing a concept called behavioral code analysis that uncovers the impact your work has on the system as a whole. Let’s see why that’s important.
From Ceremonies to Value
As an organization decides to go agile two things happen. First we learn that cultural change is hard. That means many of the principles and values of agile methodologies either get ignored or are slow to spread throughout the organization. In contrast, superficial change is easy, so ceremonies like stand-up meetings, story point guesstimates, retrospectives, etc. take off immediately.
Of these ceremonies, retrospectives are the most important: no matter what methodology you use, agile or not, taking a step back, reflecting on what you do and trying to improve from there is a fundamental learning principle. Ironically, retrospectives are also the first practice that tends to get abandoned as the agile train rolls on in an organization.
The most common reasons that retrospectives tend to get dropped after a few sprints are that:
- They’re easy to skip: Retrospectives are a team internal practice with no external deliverable. That is, no one will shout at you if you drop retrospectives. That alone makes retrospectives the first victim of a deadline.
- Static discussions and boredom: The discussions in a retrospective tends to stabilize after a few iterations/sprints. Without any new issues, the team perceives no real value in rehashing the same topics over and over again.
- Lack of effect: Like any other information generating activity, the output of a retrospective needs to be translated into actions. If the team members raise issues, they also need to see that their feedback is taken seriously and acted upon.
The reason so many organizations fall into these traps is because retrospectives tend to focus on what’s tangible and visible. So in most retrospectives I’ve taken part in, we used to discuss the outcome of the planning, suggest improvements to our way of working, and of course debate why we failed to meet the goal of the sprint. Again.
What’s visual is usually the superficial issues since the complex, dynamic aspects of our work – the ones that constantly change and require our attention – are hidden and hence absent from the discussions. Most notably, the code itself, the system we build, tends to be sadly absent. We need to change that.
So what if a retrospective lets the code take a well-deserved center stage? That is, we focus the discussion around the system each team tries to build. After all, our practices, plans, sprints, teams, etc are all mere means to the goal of delivering working software. Let’s see how.
Uncover your behavioral patterns in each sprint
A number of years ago I started to apply the ideas that eventually became Your Code as a Crime Scene to retrospectives. We found that approach so valuable that we decided to support retrospectives directly in the CodeScene analysis tool. Let’s see what it gives you.
CodeScene is a visualization and analysis tool that operates on the evolution of a codebase. By taking the history of the code into account, CodeScene can prioritize technical debt and code quality issues based on an expected return on investment. By tapping into version-control data, CodeScene can also measure social and organizational aspects of a system, which are usually at least as important as the code itself.
CodeScene is typically scheduled to run analyses at regular intervals, often as part of a continuous integration pipeline. However, we can also request a special retrospective analysis as shown in the next figure.
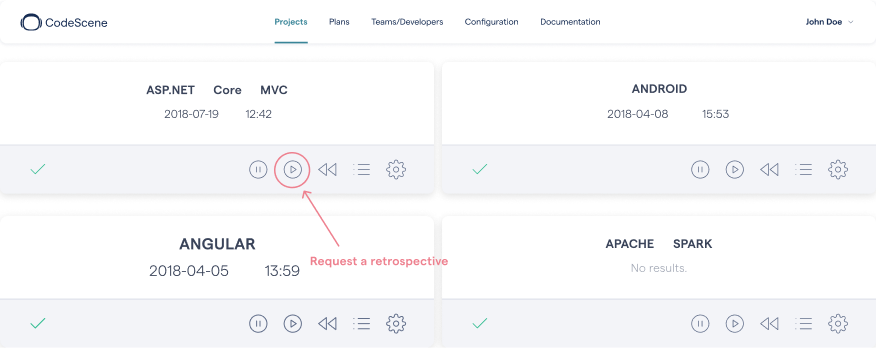
Launch a CodeScene retrospective.
Once we press that retrospective button, CodeScene runs an analysis on your team’s development activity over the last sprint. That means you get data on how your development efforts, features and stories actually impacted your codebase.
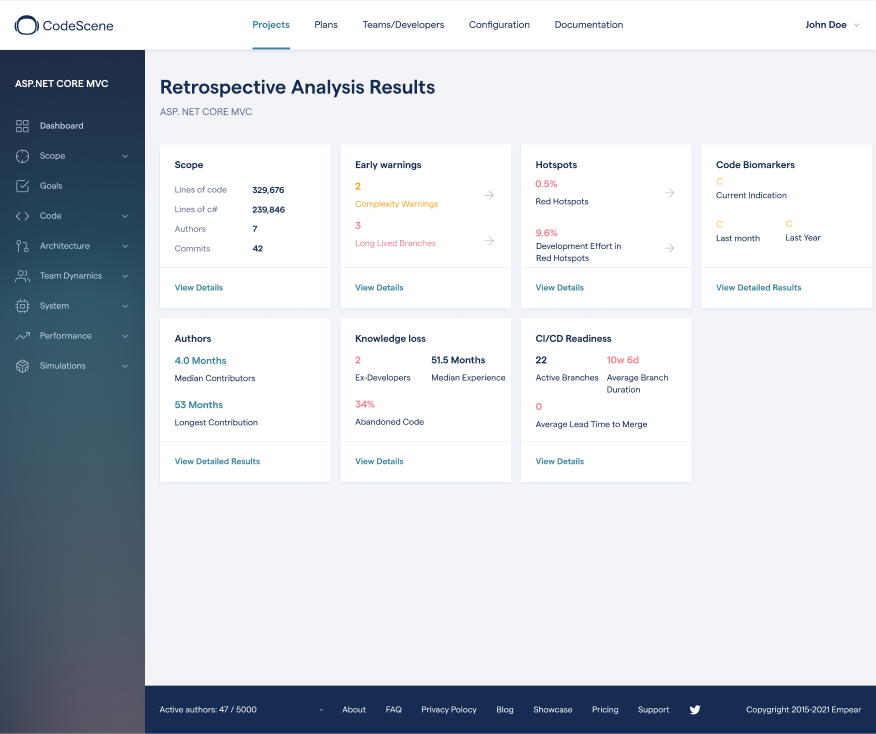
The CodeScene dashboard for a retrospective analysis.
You see the result of a retrospective analysis in the image above. There’s a lot of data on that dashboard so let’s dig into some of the highlights and how to interpret the information.
The Value of Hotspots in a Retrospective
A hotspot analysis visualizes the development activity in your codebase. Each file is represented as a circle whose size reflects the complexity of the code in that file. The more you have worked on a piece of code in the sprint, the more red the circle becomes.
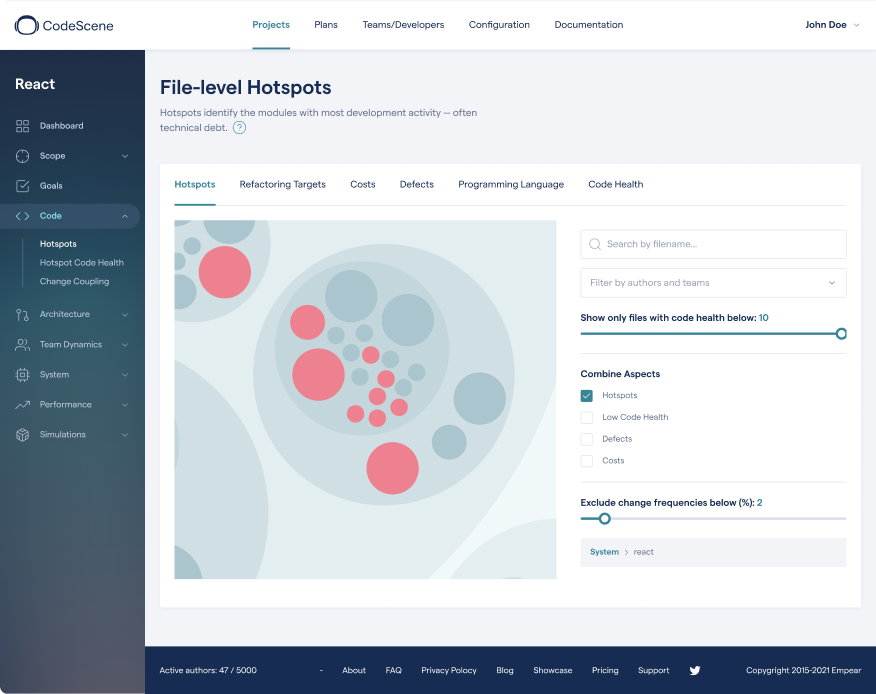
A hotspot visualization of the work done in a sprint.
The hotspot analysis provides an excellent starting point for your retrospective. Gather the team around the interactive hotspot map and see how your recent work affected the code. Your user stories and features are all fresh in memory
and here we capitalize on that. Used this way, a hotspot analysis helps you ask the right questions:
- Did your new features impact isolated parts of the system or did they spread across the entire architecture?
- Are there parts of the code which are starting to become complicated?
A hotspot analysis also primes you for the upcoming planning stage of the next iteration. If you see that a new feature impacts a hotspot rich area of the code, you use that information to plan larger refactorings and schedule additional time for the task.
Of course, a hotspot analysis is only a starting point for the conversation. You can dig deeper by inspecting the complexity trend of each hotspot. A complexity trend shows you the direction a hotspot is evolving in: does the code keep accumulating complexity or have we done any refactorings to it?
Complexity trends are generated by extracting each historic revision of a hotspot from version-control and calculating its code complexity at specific sample points, as shown in the next figure.
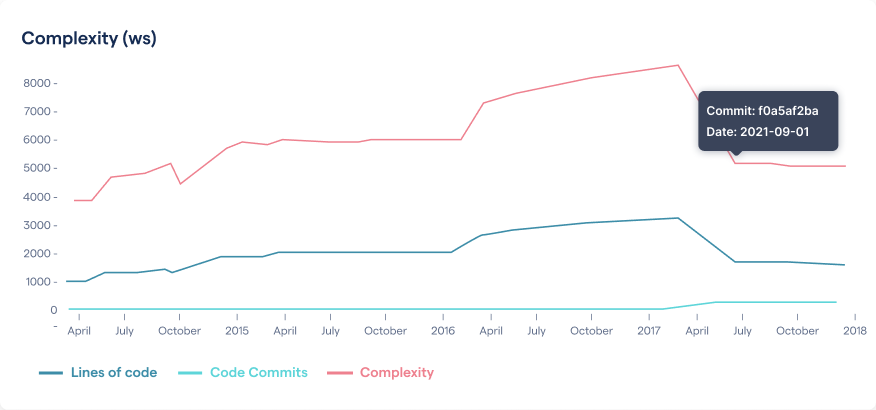
This complexity trend shows that the hotspot has been refactored.
The preceding complexity trend shows that one of our hotspots has been refactored with a significant reduction in code complexity. This is wonderful – let’s celebrate! Measuring and visualizing improvements is as important as detecting problems; larger refactorings are usually an iterative process that stretches over time, and visualizing the effect is both valuable feedback that the efforts are on track and a motivation boost to the team.
Complexity trends also let you spot problems early when you can still act upon them. You see an example in the next figure.
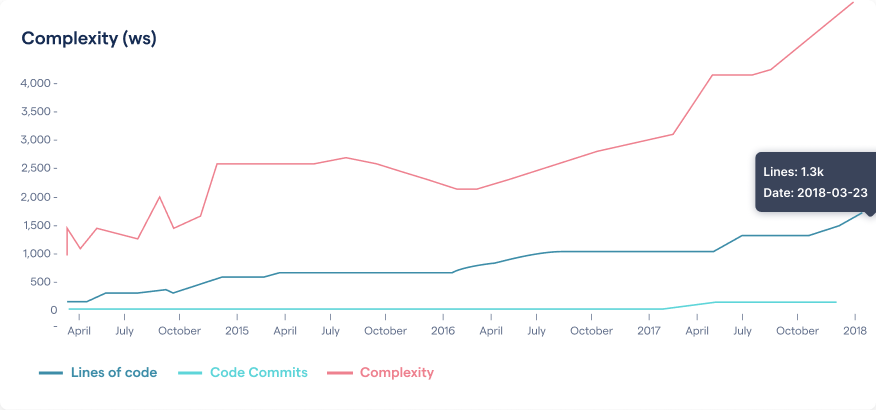
This complexity trend shows a hotspot that just keeps accumulating complexity.
This complexity trend represents a warning sign: we have a hotspot, so we know that this is code we work on a lot, and as we do, its complexity keeps increasing. We react to this finding by inspecting the code to see if it requires any proactive refactorings to bring it up to par. A behavioral code analysis simplifies that task through something called an X-Ray analysis:

An X-Ray analysis detects hotspots on a method level.
An X-Ray analysis basically parses each historic revision of the code, looks where each modification was done, and presents hotspots on a method level. This gives us a way to prioritize actionable refactorings based on how we – as an organization – actually work with the code.
You see an example in the preceding figure, where the method GenerateInput from ASP.NET MVC Core, a C# codebase, has been modified 22 times and has accumulated a high degree of complex constructs. At this point you might also ask CodeScene to join as a virtual team member and comment on the code. Here’s what it looks like:

CodeScene comes with a built-in virtual code reviewer.
Now, CodeScene is a tool, so it lacks the context that you and your team has. Its advantage is that it’s objective and might pick up details a human would miss. For example, in the preceding figure, you see that GenerateInput is highlighted as a Brain Method. A brain method is a code smell since it centers much of a class’s responsibilities to a complex method, with the consequence that each modification needs to touch this very method. This pretty much confirms what we found in the X-Ray analysis above. But the virtual code reviewer also identified a potential problem with the cohesion of the class. Its comment that the class seems to have “at least 4 different responsibilities” suggests a refactoring; Maybe we should plan to split this class into multiple, separate units?
From here you pull up the code behind the module and let the team discuss it. These steps ensure that everyone gets a shared understanding of the code quality in the project and also helps visualize the impact of all those small code additions done over several commits. A hotspot might become a boiling frog and complexity trends gives you a way to detect and reverse any decline in code quality.
Hotspots are always a good starting point for a code discussion. But in larger organizations the code doesn’t tell the whole story, so let’s glance at some social metrics and how they play well with retrospectives.
Balance your architecture and organization
So far we’ve discussed analyses that provide information to a specific development team working in a larger ecosystem. But a behavioral code analysis has a wider audience too. That’s why I recommend a retrospective from an organizational perspective as well. Usually, this retrospective targets a different stakeholder such as a cross-organizational team of architects, technical leaders, and/or the CTO. Let’s see why.
Developers tend to organize into multiple teams. These teams are typically formed around either feature areas or along the technical axes of your codebase. In some more problematic cases a team is just an organizational unit without any relationship to the way the system is designed. This later case is a sure sign of trouble as it will lead to conflicting changes to the code done by independent teams working on separate features. That in turn will increase the coordination overhead, and before you know it your calendar is filled with synchronization meetings. As if that wasn’t painful enough, such organizational issues limit your technical work as refactorings and re-designs become virtually impossible.
Most organizations are aware of these issues and try to address them. However, for a long time, such decisions have been based on subjective reports and gut feelings since the social aspects of software design are invisible in the code itself. Once we embrace behavioral code analysis, that’s no longer true.
Tools like CodeScene build on version-control data, and that means it’s possible to mine social information about the organization. With version-control data we know who worked where and when. We use that information to aggregate individual contributors into teams. Once we’ve taken that step we enable a radically different view of our code as shown in the next figure.

Identify team coordination bottlenecks.
The above figure shows an analysis of inter-team coordination needs over a sprint on a per sub-system basis. The data from the analysis is mined from version-control, and the contributions to individual files are aggregated into logical components. A logical component is any architectural boundary that carries a higher level meaning in your context. For example, in an MVC architecture, each layer would be a logical component and in a microservice architecture, each service would a component.
This analysis is useful to detect sub-systems that become coordination bottlenecks for the development teams in a sprint. The way you read the data is that the more red, the more different teams work in that part and the lower the team autonomy. In this example, we note that the Jenkins plugin has attracted contributions from three different teams. Maybe that’s fine and it meets your expectations as an organization. Or maybe that Jenkins Plugin lacks a clear ownership? Or could it be that the component has too many responsibilities and hence attracts multiple teams? A social view of code helps us ask the right questions.
Support your decisions with data
Once we start to use data on how our system evolves we make an important shift. We move away from speculations and reduce a number of social biases in the process. This is important as the traditional format of retrospectives – like most group activities – makes us sensitive to a number of biases such as availability heuristics, pluralistic ignorance, social desirability, and the classic confirmation bias. A behavioral code analysis reduces those biases. Its information might be painful at times, but it’s hard to argue with data… particularly when it’s your own.
Learn More
I hope you enjoyed this quick tour through the fascinating field of behavioral code analyses. If you want to dig deeper, then my new book, Software Design X-Rays: Fix Technical Debt with Behavioral Code Analysis, explains the analyses and their applications in more detail along with several other techniques.
If you want to try the CodeScene tool, then is available in both an on-prem version and as a service that’s free for open-source projects at codescene.io.

