This article shares my experience with the Code Health concept, and explores how it supports both developers and technical leaders with a continuous feedback loop for engineering decisions based on data.
What’s a good code health score?
Code Health correlates with Development Costs and Delivery Risks
Many organizations struggle with technical debt and code quality issues. I used to wrestle with the same challenges myself: What shall we prioritize? Where do we start? While traditional code analysis tools are good for the details, they simply weren’t intended to prioritize technical debt; getting a list of 3,000 major issues won’t help anyone.
CodeScene was developed to address these challenges by automatically prioritizing technical debt based on development hotspots. Using hotspots, you can detect an overlap between complex code that developers also have to work on often. That’s code where paying down debt has a real impact. The Code Health metric was designed to complement hotspots by providing that assessment in an automated and reliable way. That combination also limits false positives to what’s actionable.
The Code Health scale goes from 10 (healthy code that’s relatively easy to understand and evolve) down to 1, which indicates code with severe quality issues. CodeScene calculates code health using a combination of both properties of the code as well as organizational factors. The factors are chosen based on research, and known to correlate with increased maintenance costs and the risk for defects (some common examples include detecting Brain Methods, DRY violations, Developer Congestion, Knowledge Distribution, etc.). CodeScene then weights and scores the findings according to an extensive set of baseline data from real-world codebases to come up with the normalized code health metric.
This makes it possible to get an overall code health summary of the hotspots. Using this view, you can immediately detect where the most likely technical bottlenecks are across your codebases:
Measure and compare code health across codebases to detect
the most likely technical bottlenecks.
Before we dig deeper, let me explain the reasoning behind the Code Health vocabulary. We wanted to avoid overly general terms like “quality” or “maintainability” since they are contextual, poorly defined, and suggest an absolute truth. Instead, I found that it’s the trend that’s important: Is the code evolving in the desired direction? Are our development hotspots getting better or worse? Code Health aligns nicely with this reasoning and introduces a positive vocabulary. Let’s get specific by looking at an example from Facebook’s React codebase:
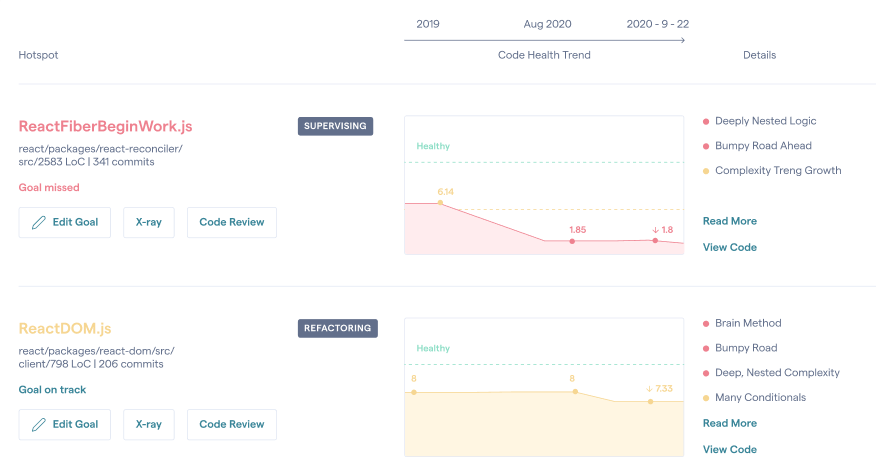
Code health trends of the hotspots in the React codebase (example).
The previous figure shows an example on two files, one with a code health of 1.8, and one with a better health of 7.33. Are those numbers good or bad? To answer that question we need to look beyond absolute numbers. Let’s see why and how.
Trends are actionable
When analysing code, I always emphasize trends over absolute values; is it getting better or worse?
The impact of Code Health issues are Contextual
First of all, code quality is contextual. All larger codebases that I have seen had their fair share of quality issues. The thing is that an organization can – and often does – live with a certain amount of code quality issues and technical debt. At least as long as those issues are in the right parts of the code; stable and well-understood areas. On the other hand, even a minor amount of technical debt can quickly become expensive if it’s in a development hotspot. That’s why CodeScene focuses code health measures on hotspots, not any code in general.
Second, once a hotspot has declined in code health it tends to stay that way; the cost to restore its health will always compete with more pressing immediate concerns, quite often the drive for new features. This means that anything you can do to provide an early detection mechanism is valuable. That way, your organization can do pro-active refactorings while they are still affordable and avoid future maintenance headaches.
Looking back at the React example, we see that the first hotspot, ReactFiberBeginWork.js, had a better health back in 2019, scoring 6.14. So sometime during the past year that code declined in health. Was it a boiling frog problem with the code getting gradually harder to understand? Or was it a big bang change that took a hit on the overall health? No matter the root cause, both patterns can be caught early before the code is merged. Here’s how it’s done.
Supervise Code Health in Pull Requests
CodeScene integrates with pull request to provide a short feedback loop. That way, CodeScene can act as a (soft) quality gate during development. If a hotspot declines in health, CodeScene detects it and informs. Here’s an example from how it looks in GitHub’s Checks API (other integrations like BitBucket, GitLab, and Azure DevOps are available too, of course):
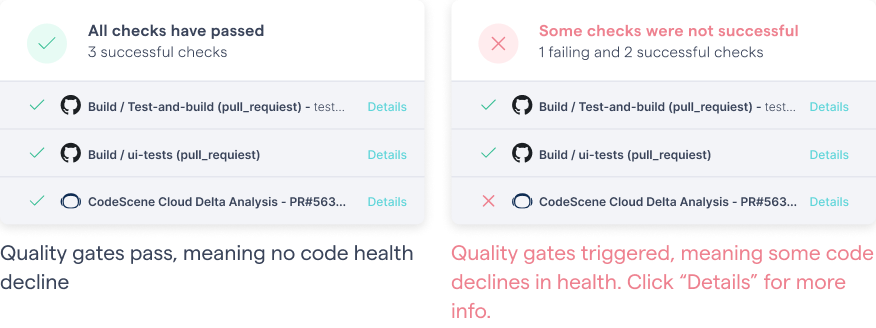
CodeScene’s quality gate triggers in a GitHub check on code health decline.
As a developer, I can now click on the Details and get an explanation of the detected code health decline. This is information that forms the basis for conversations: is the feature so important that your organization is prepared to take a code health hit? Or should we get back to the drawing board and see if we can refactor the code now while it’s still fresh in our head and affordable to do so? No matter the decision, you will no longer take on any reckless technical debt unless you actively chose to do so.
Nothing tastes better than Dog Food
At CodeScene the company, all developers are using CodeScene themselves, including the Pull Request integration and quality gates. This helps us focus code reviews to where they are needed the most. It’s also motivating to see a trend moving in the right direction; refactoring code is always challenging, and having positive reinforcements is valuable feedback too.
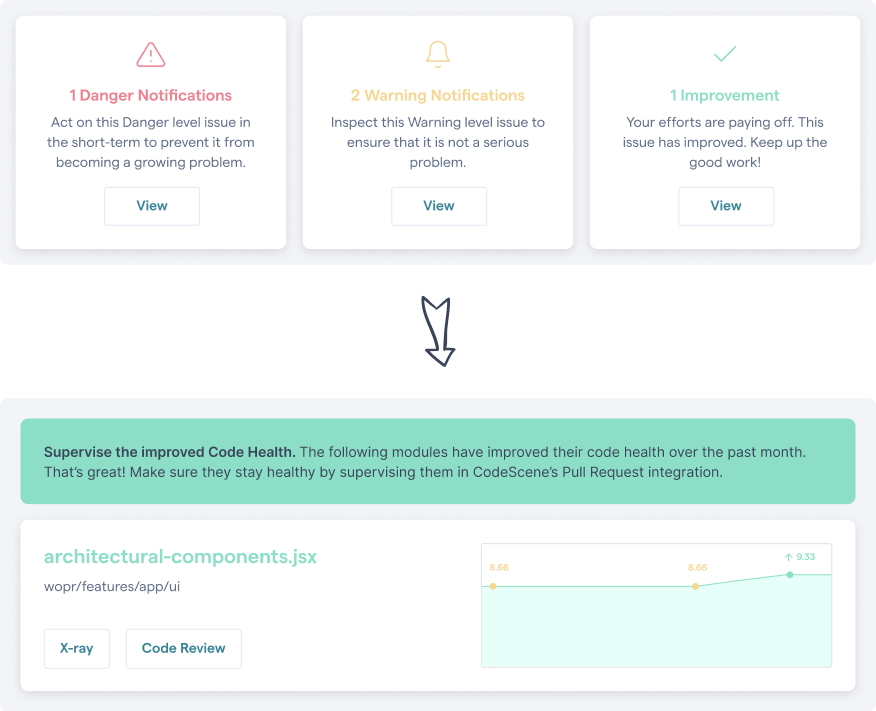
Get positive reinforcements on refactorings and design improvements
that improve the code health.
Code health for technical leaders
In my role as CTO, the combination of Hotspot information with Code Health trends has been a game-changer. Being able to move forward quickly is vital for a product company, and I use this information regularly to decide when we can continue to push forward with new features, and when – and where – we need to take a step back and invest in improvements. It’s a delicate balance that shifts over time, and having real-time data on the effects of our development is invaluable.
Do you also track the code health of your hotspots?

