Complex code slows down development productivity, increases the delivery risk, and leads to excess maintenance costs.
However, despite its importance, code complexity remains a vaguely defined concept. More specifically, cyclomatic complexity – the most popular metric in our industry – has severe limitations that makes the measure only marginally better than simply counting the lines of code in a function.
In this article we’ll take a fresh look at code complexity to define the Bumpy Road code smell. Along the way, you will see that absolute complexity numbers are of little interest; it’s much more interesting how that complexity is distributed and in what shape it manifests itself.
By identifying patterns in code complexity structures, we can come up with measures that are better aligned with how our brain works, and hence provide a more relevant alternative than traditional complexity metrics. Let’s start by discussing the limits of today’s metrics.
Cyclomatic Complexity is a poor Predictor of Code Complexity
Cyclomatic Complexity was introduced back in 1976 as a quantitative metric of code complexity. Basically, cyclomatic complexity counts the number of logical paths through a function. That is, each if-statement, each control structure like a for or while loop adds complexity. We count them and sum it up to get a complexity value. Simple enough.
Only, it really isn’t. Two different functions might have the same cyclomatic complexity value, yet one is significantly more complex than the other. The canonical example is to compare a straightforward swith-case chain with a bubble sort implementation:

Cyclomatic complexity really doesn't tell much about the effort to understand a piece of code.
Looking at the previous example, it’s clear that cyclomatic complexity doesn’t reveal much about the relative effort required to understand or modify a piece of code. More specifically, cyclomatic complexity doesn’t account for nested coding constructs. And that’s unfortunate, because nesting conditional logic is what truly drives complexity. Let’s see why.
Nesting Conditional Logic Taxes Our Working Memory
When we implemented CodeScene’s Code Health metric, our ML algorithms ended up weighting cyclomatic complexity very low; the predictive value of cyclomatic complexity wasn’t good, except as an indication on how many unit tests you would need in order to cover all execution paths of a function. Instead, we ended up weighting nested complexity much more heavily. There’s a very good reason for this, and it all relates to how our brains are wired.
Let’s face it: the human brain is the most limiting factor we have in programming. From a cognitive perspective, one major bottleneck when reading code is a construct called working memory. Working memory is the mental workbench of the mind. It’s working memory that we use to perceive, integrate, and manipulate information in our head. Working memory is vital to us as software developers.
Unfortunately, working memory is also a strictly limited cognitive resource; there’s only so much information that we can hold in our head at once and reason about effectively. In fact, modern cognitive psychology paints a rather depressing picture. Depending on the type of information, our working memory might be limited to as little as 3-4 items. Now, let’s consider that bottleneck in the context of nested conditional logic:
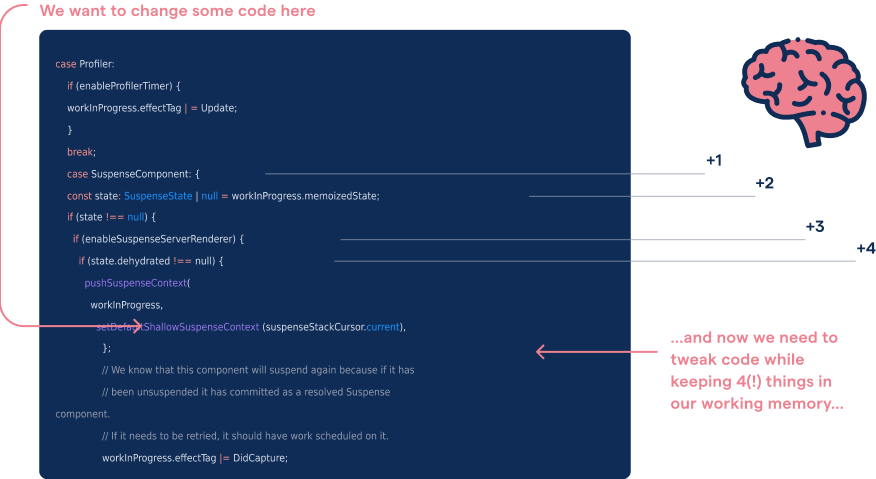
Nested conditional logic puts a heavy tax on our working memory (example from React).
Given these cognitive limitations, it’s no wonder that nesting complexity has a high correlation to defects. Identifying nested logic is a valuable starting point, but we need to do better. Let’s see how by introducing the Bumpy Road code smell.
Introducing the Bumpy Road Code Complexity Pattern
If nested conditional logic is problematic, functions that contain multiple blocks of nested logic are true obstacles to evolvable code. Looking at their shape and distribution of complexity, such functions are like bumpy roads to a development team; they force us to slow down, and they don’t allow for a slight slip of attention.
The Bumpy Road code smell is a function that contains multiple chunks of nested conditional logic. Just like a bumpy road slows down your driving, a bumpy road in code presents an obstacle to comprehension. Worse, in imperative languages there’s also an increased risk for feature entanglement, which tends to lead to complex state management.

The Bumpy Road code smell is a function that contains multiple logical chunks of logic, driving the real code complexity (example from React).
Fundamentally, a bumpy code road represents a lack of encapsulation which becomes an obstacle to comprehension. Worse, in imperative languages there’s also an increased risk for feature entanglement, which tends to lead to complex state management.
When inspecting bumpy code roads, I follow a set of simple rules to classify the severity of the code smell:
- The deeper the nested conditional logic of each bump, the higher the tax on our working memory.
- The more bumps we find, the more expensive it is to refactor as each bump represents a missing abstraction.
- The larger each bump – that is, the more lines of code it spans – the harder it is to build up a mental model of the function.
Tools to Detect and Measure the Bumpy Road Code Smell
Over the past five years I have analyzed hundreds of codebases. Using hotspots, I can quickly identify the most interesting parts of the code, the parts that tend to drive maintenance costs and risks. Using the Code Health metric, I then focus my attention on the code likely to represent the worst offenders.
This experience drove me to capture the bumpy road code smell. I simply noticed that some functions were so much harder to understand than others, despite similarities in size and absolute complexity values. As outlined in this article, absolute numbers are of little interest when it comes to code complexity. All that matters is how that complexity is distributed and how that in turn shapes the code.
Hence, it was natural to expand our tooling to automatically detect bumpy roads in code. Here’s what it looks like in CodeScene:

The CodeScene tool auto-detects the Bumpy Road code smell (example from React)
.
After implementing the bumpy road code smell detection, we made sure to re-train our code health classification algorithm so that it takes bumpy roads into consideration. As it turned out, bumpy roads are one of the best predictors of code that is hard to understand and, hence, expensive to maintain and risky to evolve with new features. Fortunately, the remedy is usually straightforward; the EXTRACT METHOD refactoring is the primary weapon of counter-attack. A few iterations later, and you have turned a previously bumpy road into a code reading highway.

